企業(yè)級監(jiān)控告警產品專題(2): IaaS層監(jiān)控設計概述——基礎軟件服務
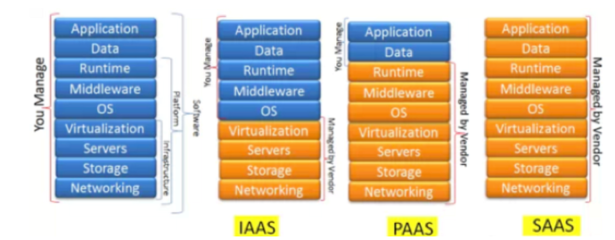
在構建企業(yè)級IT基礎設施即服務(IaaS)監(jiān)控體系時,除了對物理硬件、虛擬化資源等底層組件的監(jiān)控,對運行其上的基礎軟件服務的監(jiān)控同樣至關重要。這些基礎軟件構成了應用運行的直接環(huán)境,其健康度、性能與可用性直接影響上層業(yè)務的穩(wěn)定性。本文將聚焦IaaS層中基礎軟件服務的監(jiān)控設計,探討其核心監(jiān)控對象、關鍵指標與設計原則。
一、核心監(jiān)控對象
IaaS層的基礎軟件服務通常包括但不限于以下幾類:
- 操作系統(tǒng):如Linux、Windows Server等,是承載一切應用的基石。
- 虛擬化管理程序:如VMware vSphere、KVM、Hyper-V等,負責虛擬資源的調度與管理。
- 容器運行時與編排平臺:如Docker、Kubernetes,在現(xiàn)代云原生架構中日益普及。
- 基礎中間件:如數據庫(MySQL, PostgreSQL, Redis)、消息隊列(Kafka, RabbitMQ)、Web服務器(Nginx, Apache)等,為應用提供通用服務能力。
二、關鍵監(jiān)控指標體系
針對上述對象,監(jiān)控設計需覆蓋多維度指標,形成立體化視圖:
- 可用性與狀態(tài)監(jiān)控:
- 服務進程狀態(tài):關鍵進程是否在運行、是否頻繁重啟。
- 端口監(jiān)聽狀態(tài):服務是否在預期端口正常監(jiān)聽。
- 日志錯誤匹配:實時掃描系統(tǒng)日志與應用日志,捕獲致命錯誤、頻繁警告等模式。
- 性能與資源監(jiān)控:
- 系統(tǒng)資源:CPU使用率、內存使用與交換情況、磁盤I/O吞吐與延遲、網絡帶寬與連接數。對于容器環(huán)境,需關注Requests/Limits的使用情況。
- 服務內部指標:如數據庫的查詢速率、慢查詢數量、連接池使用率;消息隊列的堆積長度、生產消費速率;Web服務器的請求處理速率、錯誤碼分布(如5xx比例)。
- 響應時間:服務關鍵操作或接口的響應延遲,如數據庫查詢耗時、API接口響應時間。
- 容量與趨勢監(jiān)控:
- 磁盤容量增長趨勢預測。
- 數據庫表空間使用率、數據增長趨勢。
- 連接數、線程數等資源使用的歷史趨勢與預測,助力容量規(guī)劃。
- 配置與合規(guī)監(jiān)控:
- 關鍵配置文件變更審計。
- 系統(tǒng)參數檢查(如Linux內核參數、數據庫配置參數是否符合最佳實踐或安全基線)。
三、監(jiān)控設計核心原則
- 無侵入與低開銷:監(jiān)控代理或采集器應盡可能輕量,避免對基礎軟件本身性能造成顯著影響。優(yōu)先使用服務本身提供的指標接口(如StatsD、JMX、Prometheus metrics端點)。
- 關聯(lián)性分析:建立資源與服務的關聯(lián)拓撲。當一臺宿主機出現(xiàn)高負載時,應能快速關聯(lián)顯示其上運行的所有虛擬機或容器及其服務的健康狀況,實現(xiàn)根因快速定位。
- 智能化閾值與動態(tài)基線:避免僵化的靜態(tài)閾值。利用機器學習算法,分析指標歷史數據,建立動態(tài)基線,實現(xiàn)基于趨勢和模式的異常檢測,減少誤告警。
- 可觀測性集成:將指標(Metrics)、日志(Logs)、鏈路追蹤(Traces)數據進行關聯(lián)整合。當指標出現(xiàn)異常時,可一鍵下鉆查看相關錯誤日志或慢請求追蹤詳情,加速問題排查。
- 主動預防與自動化:監(jiān)控不僅用于告警,更應服務于優(yōu)化與預防。例如,根據磁盤使用趨勢預測,在容量耗盡前自動觸發(fā)擴容流程或通知運維人員。
四、告警設計要點
- 分級分類:根據服務重要性和影響范圍,將告警劃分為緊急、重要、警告等不同等級,并匹配不同的通知渠道(如短信、電話、郵件、IM工具)。
- 降噪與聚合:避免告警風暴。對同一根因引發(fā)的多條告警進行智能聚合;設置合理的告警冷卻期;支持維護期靜默。
- 上下文豐富化:告警信息中應附帶相關的指標圖表、拓撲位置、近期變更記錄等上下文信息,使接收者能快速理解問題。
- 與運維流程聯(lián)動:告警應能自動創(chuàng)建故障工單,或觸發(fā)預定義的修復腳本(如服務重啟、節(jié)點隔離),實現(xiàn)部分場景的自動愈合(Auto-remediation)。
IaaS層基礎軟件服務的監(jiān)控是企業(yè)監(jiān)控體系的承重墻。它要求設計者不僅深入理解各類軟件的技術細節(jié),更需具備平臺化思維,將分散的指標、日志、事件有機整合,通過智能分析形成洞察,最終目標是從被動響應走向主動保障與優(yōu)化,為企業(yè)的數字化轉型提供堅實、可信的底層支撐。
如若轉載,請注明出處:http://www.ganzhouwuliu.cn/product/40.html
更新時間:2026-01-21 06:47:34